无
”Spark Python“ 的搜索结果

Spark是一个开源的大数据处理框架,它提供了高效的分布式算能力,可以处理大规模的数据集。而Python是一种简单易学的编程语言,具有丰富的数据处理和分析库。Spark Python(PySpark)是Spark的Python API,它允许...
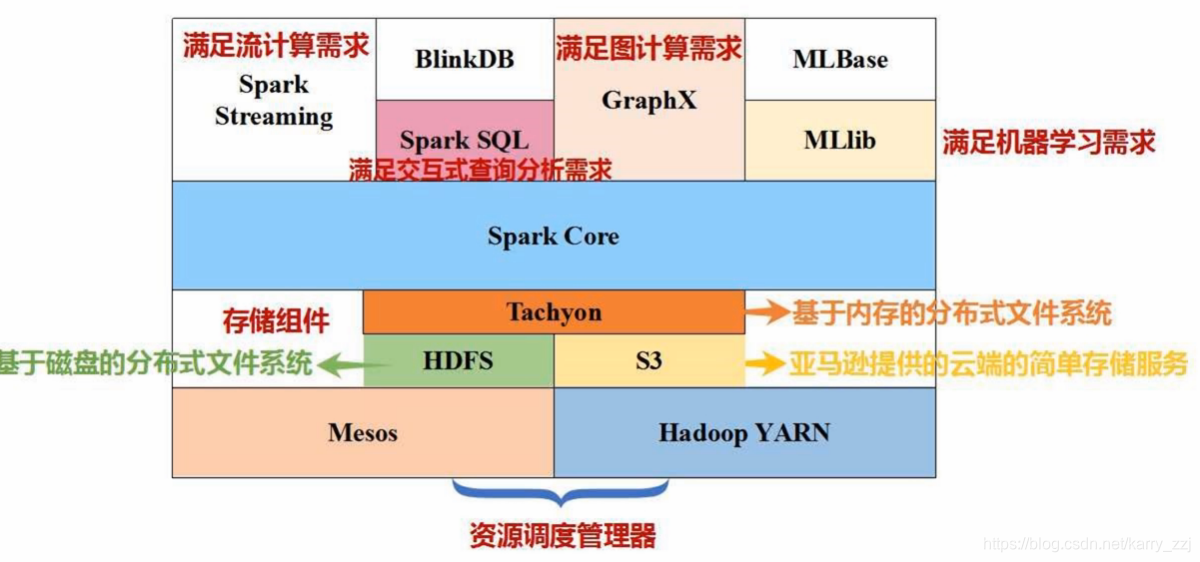
Spark是2015年最受热捧大数据开源平台,我们花一点时间来快速体验一下Spark。Spark 技术栈如上图所示,Spark的技术栈包括了这些模块:核心模块 :Spark Core集群管理Standalone SchedulerYARNMesosSpark SQLSpark 流...
http://blog.csdn.net/ydq1206/article/details/51922148 转载于:https://www.cnblogs.com/wcLT/p/6428163.html
spark能跑Python么?spark是可以跑Python程序的。python编写好的算法,或者扩展库的,比如sklearn都可以在spark上跑。直接使用spark的mllib也是可以的,大部分算法都有。Spark 是一个通用引擎,可用它来完成各种各样...
构建PySpark环境首先确保安装了python 2.7 ,强烈建议你使用Virtualenv方便python环境的管理。之后通过pip 安装pysparkpip install pyspark文件比较大,大约180多M,有点耐心。下载 spark 2.2.0,然后解压到特定目录,...
我尝试在spark作业中运行并行线程。当我从cli运行python脚本时,这一点毫无问题,但我的理解是,这并没有真正利用EMR集群并行处理的好处。当我作为spark作业运行时,它实际上并没有保存数据。当我把它作为spark作业...
pandas、spark计算相关性系数速度对比相关性计算有三种算法:pearson、spearman,kenall。在pandas库中,对一个Dataframe,可以直接计算这三个算法的相关系数correlation,方法为:data.corr()底层是依赖scipy库的...
事由上周工作中遇到一个bug,现象是一个spark streaming的job会不定期地hang住,不退出也不继续运行。这个job经是用pyspark写的,以kafka为数据源,会在每个batch结束时将统计结果写入mysql。经过排查,我们在driver...
在数据挖掘中,Python和Scala语言都是极受欢迎的,本文总结两种语言在Spark环境各自特点。1.性能对比由于Scala是基于JVM的数据分析和处理,Scala比Python快10倍。当编写Python代码用且调用Spark库时,性能是平庸的,...
在下spark新手,最近一直在学习,用pyspark跑了一些例子,都没有问题,但是运行ml例子中的random_forest_example.py的时候却出现如下错误:py4j.protocol.Py4JJavaError: An error occurred while calling z:org....
---------------------------------------------------------------------------Py4JJavaErrorTraceback(most recent call last)in()---->1data.first()C:\Spark\python\pyspark\rdd.pycinfirst(self)1313ValueEr...
0.参考文章1.pyspark练习进入到spark目录,然后采用默认的设置运行pyspark./bin/pyspark配置master参数,使用4个Worker线程本地化运行Spark(local[k]应该根据运行机器的CPU核数确定)./bin/pyspark –master local[4]...
A Spark newbie here.I recently started playing around with Spark on my local machine on two cores by using the command:pyspark --master local[2]I have a 393Mb text file which has almost a million rows...
我试图count使用Spark API对mllib的FP growth生成的频繁项集。我的火花是1.5.1版。以下是我的代码:#!/usr/bin/pythonfrom pyspark.mllib.fpm import FPGrowthfrom pyspark import SparkContext,SparkConffrom ...
首先,你必须知道不同类型的API(RDD API,MLlib 等),有它们不同的性能考虑。RDD API(带JVM编排的Python结构)这是一个会被Python代码性能和PySpark实施影响最大的组件。虽然Python性能很可能不会是个问题,至少...
例如-在Spark Streaming中,我有以下形式的传入数据-{"id": xx,"a" : 1,"b" : 2,"c" : 3,"d" : 4,"scores"{"score1" : "","score2" : "","score3" : ""}}处理它的管道如下-^{pr2}$因为我所有的RDD都是串行创建的,...
Spark新手在这里.我尝试使用Spark对我的数据框执行一些pandas操作,并且令人惊讶的是它比纯Python慢(即在Python中使用pandas包).这是我做的:1)在Spark中:train_df.filter(train_df.gender == '-unknown-')....
想要成为一个程序员,除了学习各种教程之外,熟悉各种已经在生产环境中使用的工具会让你更快的成长!这里有7款python工具,是所有数据专家必不可少的工具。当你对他们有一定了解后,会成为你找工作的绝对优势!...
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =。这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark SQL相关的知识,如果对Spark不熟...
java.lang.IllegalArgumentException: System memory 239075328 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.Xm在...
package com.chb.shopanalysis... import java.util.Properties; import org.apache.log4j.Logger; import org.apache.spark.SparkConf;...import org.apache.spark.api.java.JavaSparkContext;...import org.apache.sp...
目录: 简介 pyspark IPython Notebook 安装 配置 ...不可否认,spark是一种大数据框架,它的出现往往会有Hadoop的身影,其实Hadoop更多的可以看做是大数据的基础设施,它本身提供了HDFS文件系...


## yarn client hdfs文件 spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --num-executors 3 \ --executor-memory 1g \ --executor-cores 1 \ --archives hdfs://hadoop102:8020/...

1.2 Spark简介Apache Spark是为了提升Hadoop中MapReduce的效率而创建的。Spark还提供了无可匹敌的可扩展性,是数据处理中高效的瑞士***,提供SQL访问、流式数据处理、图计算、NoSQL处理、机器学习等功能。...
推荐文章
- javafx预览PDF_javafx pdf-程序员宅基地
- ipv4与ipv6访问_纯ipv4访问纯ipv6-程序员宅基地
- css强制换行-程序员宅基地
- 链霉亲和素修饰的CdSe–ZnS量子点-程序员宅基地
- 饿了么4年 + 阿里2年:研发路上的一些总结与思考-程序员宅基地
- vue的sync语法糖的使用(组件父子传值)_sync传值-程序员宅基地
- 最大流最小割_网络最大流量与割的容量的关系-程序员宅基地
- queryString模块_querystring模块安装-程序员宅基地
- 安卓电量检测工具Battery Historian的使用记录_battery-historian 电量测试-程序员宅基地
- 基于QPSK的载波同步和定时同步性能仿真,包括Costas环的gardner环_qpsk符号同步-程序员宅基地